

Выберите категорию
|
Вебинар
[158]
Вебинары по FPGA и языкам проектирования для ПЛИС
|
|
Заметка
[58]
Небольшие заметки по использованию технологии FPGA/ПЛИС
|
| Руководство [53] |
|
Мероприятия
[36]
Семинары, конференции, встречи
|
|
Анонсы
[19]
Свежие новости и релизы из мира FPGA
|
|
Новинки
[63]
Новые изделия на базе FPGA
|
| Стрим [5] |
Объявления





Случайные статьи

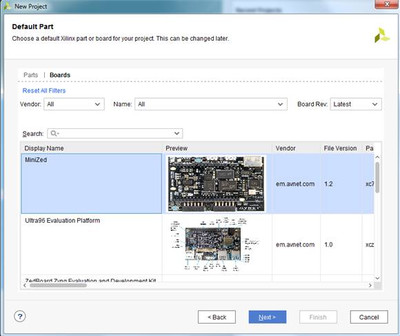
High Level Synthesis
Разработка IP-блока с помощью инструментов высокоуровнего синтеза: HLS Часть 2
Подробнее

Статистика
Архив новостей из мира FPGA

Анонс книги Параунитарные банки фильтров в алгебре кватернионов для систем кодирования изображений в ограничениях арифметики с фиксированной
Продолжаем публиковать книжные новинки и выбивать небольшие, но все же скидки на них.


122
Краткая сводка научных статей, с упоминанием FPGA/ПЛИС (Март 2024 / часть 1)
Предлагаем читателям небьольшую подборку зарубежных начно-технических статей с упоминанием ПЛИС
- Реализация гибридного метода маркировки пятен волнового фрон
...
Читать дальше »
429

0

FPGA 2024.1 : Слёт и второй номер журнала
ПЛИС-культ привет, FPGA комьюнити!
Два коротких объявления:
1. Ищем докладчиков для нашего слета FPGA разработчиков, который состоится в Москве-Питере-Новосибирсике/Томске в концеМая--началеИюня. Регистрация пока не открыта, но мы хотим сформировать программу заранее Т ... Читать дальше »
360
0
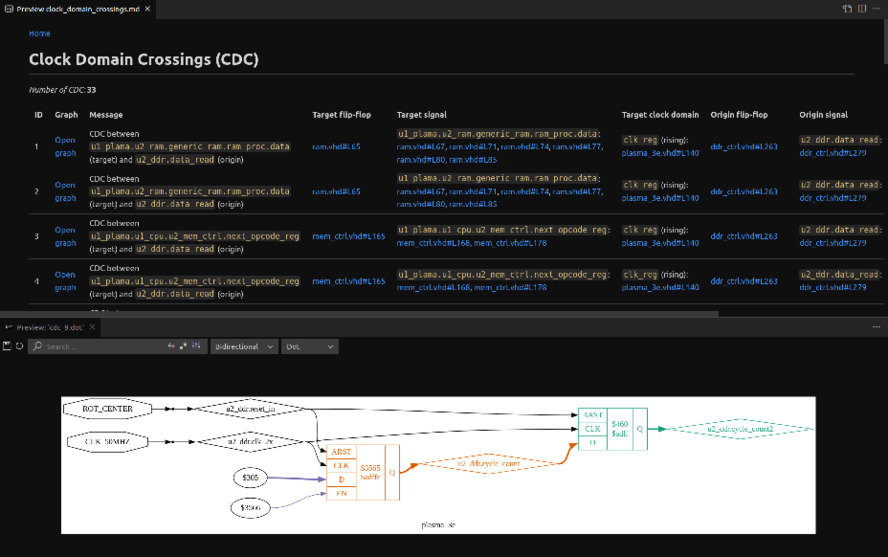

Ускорение разработки на SoC и FPGA с помощью Vitis™ Model Composer и Vivado™ Design Suite
Vitis ™ Model Composer предоставляет собой среду для разработки алгоритмов и среду проектирования на основе моделей. Vitis Model Composer также предлагает различные методы для ускорения процесса разработки и упрощения интеграции сложных IP-ядер в проекты.
На этом вебинаре мы рассмотрим: ... Читать дальше »
1674
0

ПРЕДКОНФЕРЕНЦИИ РОССИЙСКОГО ФОРУМА МИКРОЭЛЕКТРОНИКА 2023
9-я научная конференция «ЭКБ и микроэлектронные модули», фундаментальное мероприятие российского форума «Микроэлектроника 2023», включает две предконференции, которые пройдут в сентябре 2023 года.
1699
0

GOWIN Semiconductor приглашает на вебинар по i3c .
GOWIN Semiconductor приглашает на вебинар по i3c .
Компания GOWIN Semiconductor рада представить клиентам FPGA семейство продуктов I3C IP. На протяжении десятилетий I2C был широко используемым интерфейсом в электронной промышленности для настройки, сенсорного интерфейса и других приложений с низкой про ... Читать дальше »
1515
0
Бесплатные тренинги от Intel на июль
Товарищи, если вы сможете попасть на эти тренинги, поделитесь, пжлст, материалами тренинга или их записью с FPGA коммунити. Напишите мне в телегам @KeisN13 или почту admin@fpga-systems.ru Давайте сделаем бесплатные материалы тренингов доступными для всех.
1210
0

Российский форум «Микроэлектроника» - межотраслевая площадка для общения специалистов в области разработки, поставки и применения ЭКБ и РЭС
С 9 по 14 октября 2023 года в Парке науки и искусства «Сириус» пройдет одно из важнейших событий года в сфере высоких технологий − Российский форум «Микроэлектроника 2023», ставший основной межотраслевой площадкой для ... Читать дальше »
1466
0









0