Xilinx VERSAL: монстр с NoC'ом




Оглавление
Друзья. Примерно год назад компания Xilinx анонсировала свое очередное детище под названием Versal. Разумеется, такое знаковое событие не могло остаться без статьи в каком-либо техническом журнале, что и было сделано. Однако по прошествии долгого времени решили опубликовать статью на нашем ламповом ресурсе. Приятного прочтения.
Versal – адаптируема платформа ускорения вычислений
Пожалуй, наиболее интересным был анонс кристаллов с новой для Xilinx архитектурой, которые ранее были известны под кодовым названием «проект Everest» – это новое поколение, которое будет выполнено по технологии FinFET 7 нм, получило название VERSAL.
VERSAL [1] – это первая в индустрии гетерогенная платформа для ускорения вычислений, которая в прессе более известна под названием ACAP – Adaptive Compute Acceleration Platform – адаптивная платформа ускорения вычислений любых приложений, объединяющая в себе одновременно несколько различных механизмов [2] (см. рис. 1):
- Модули скалярных вычислений (Scalar Processing Engines) – это процессор приложений ARM Cortex-А72, процессор реального времени ARM Cortex-R5 и специализированный контроллер управления платформой (platform management controller).
- Модули адаптируемых аппаратных средств (Adaptable Hardware Engines) – усовершенствованное, по сравнению с предыдущими семействами, более производительное поле FPGA (Field-Programmable Gate Array), с улучшенной способностью к частичной реконфигурации, выполняемой «на лету», скорость частичной реконфигурации возросла до 8 раз.
- Модули векторной обработки (Intelligent Engines) – поле выполнения операций умножения с плавающей запятой с минимальными задержками (DSP Engines) и специализированное поле/модуль AI Engines c высокой пропускной способностью, а также минимальными задержкам на выполнение операций и оптимальным уровнем энергопотребления, предназначенное для решения задач в области реализации искусственного интеллекта (AI inference) и цифровой обработки сигналов. Данное поле в архитектуре VERSAL является новым, по сравнению с предыдущими семействами, и будет рассмотрено отдельно.
- Интегрированные интерфейсы хост-систем – как и в предыдущих семействах ПЛИС Xilinx, в архитектуре VERSAL будут поддерживаться различные аппаратные реализации для взаимодействия с отдельно стоящими процессорами: PCIe Gen4x16, интегрированный модуль AXI-DMA, CCIX для ускорения решения задач, возлагаемых на серверные центральные процессоры (CPU – central processing unit).
- Интегрированные контроллеры внешней памяти – для достижения максимальной пропускной способности и возможности работы с такими типами памяти как DDR4-3200, LPDDR-4266 и High Bandwidth Memory (HBM). В архитектуре VERSAL предусмотрены специализированные аппаратные/интегрированные контроллеры памяти, количество которых варьируется, в зависимости от кристалла.
- Интегрированные протокольные решения – для реализации высокоскоростных протоколов передачи данных предусмотрены аппаратные ядра 100 Гбит/c Multirate Ethernet, 600 Гбит/с Ethernet и Interlaken, 600 Гбит/c Cryptographic Engines (AES/IPSEC/MACSEC).
- Широкополосные трансиверы – в архитектуре VERSAL предусмотрены: оптимизированные по энергопотреблению трансиверы 32/58 Гбит/c PAM4 и 112 Гбит/c PAM4.
- Интегрированные радиочастотные блоки – multi-GSPS RF-ADC/DAC нового поколения, DDC/DUC, SD-FEC для 5G и DOCSIS.
- Программируемые блоки ввода/вывода для поддержки различных интерфейсов, среди которых MIPI D-PHY с поддержкой скорости более 3 Гбит/с на сенсор, различные низкоскоростные виды памяти типа NAND и storage-class, LVDS и I/O общего назначения.
- Сеть-на-кристалле (NoC – Network-on-Chip) – одна из особенностей кристаллов с архитектурой VERSAL, назначение которой быстрая доставка данных и обмен данными между различными частями микросхемы. Обладает пропускной способностью в несколько Тбит/с, возможностью непосредственного программирования, не требует этапа размещения и трассировки, сеть доступна при загрузке кристалла, поскольку является интегрированной шиной. Энергопотребление такой интегрированной сети по сравнению с её реализацией на ресурсах программируемой логики ниже в 8 раз. Поддерживается возможность арбитража между различными модулями.
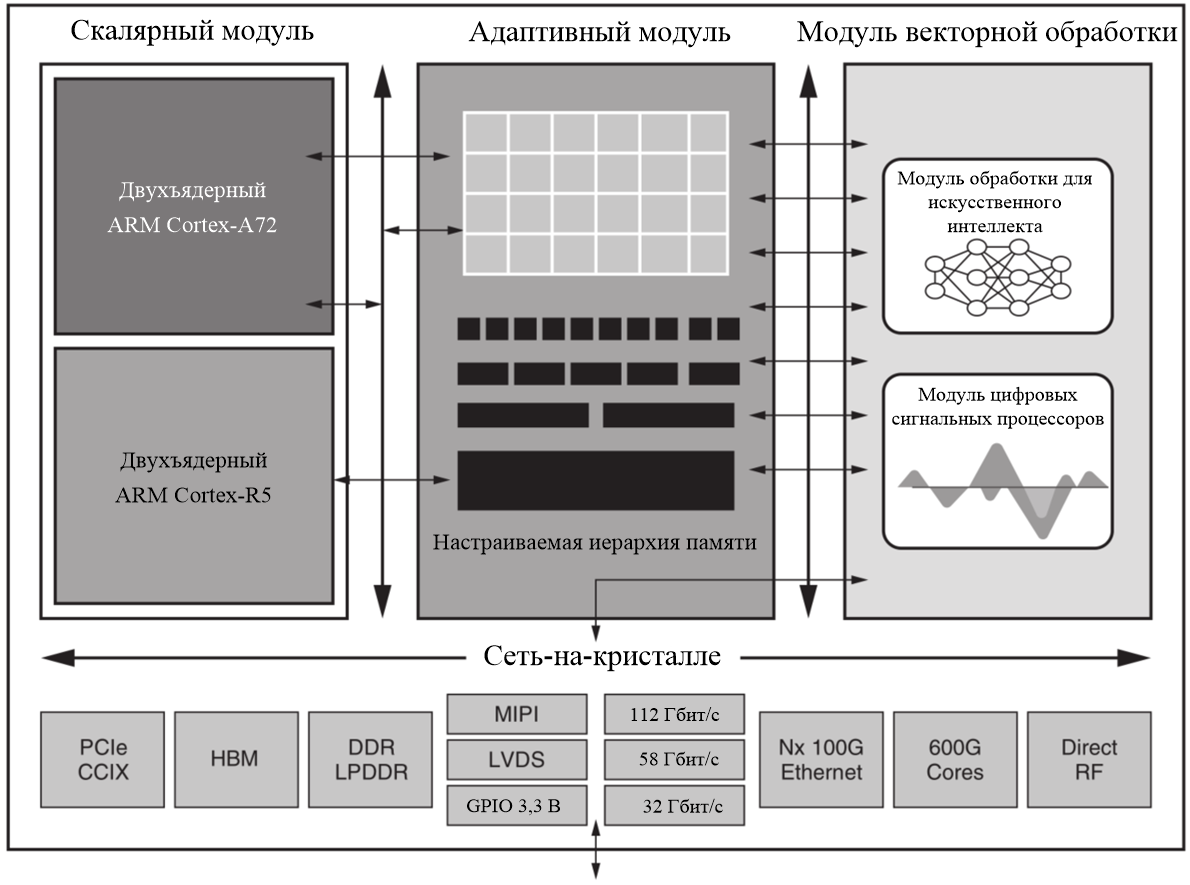
Рис. 1. Функциональная диаграмма Xilinx ACAP Versal
Однако наиболее важным является то, что для работы с новой архитектурой будут доступны различные наборы инструментов, такие как программное обеспечение, библиотеки, IP-ядра, промежуточное программное обеспечение (middleware), драйверы и различные фреймворки.
Для архитектуры VERSAL анонсировано 6 серий, которые получили индивидуальные названия и разделены по целевым направлениям [2]:
- AI RF Series;
- AI Core Series;
- AI Edge Series;
- HBM Series;
- Premium Series;
- Prime Series.
Области применения и преимущества VERSAL
Выбранные Xilinx ещё несколько лет назад целевые направления рынка остались прежними. Кристаллы архитектуры VERSAL в первую очередь ориентированы на центры обработки данных и облачные вычисления, 5G и другие беспроводные технологии, машинное обучение и высокоскоростную передачу данных по проводным каналам связи (межсерверная передача данных на скорости 400/600 Гбит/с).
Для того чтобы ответить на вопрос о выигрыше, получаемом при использовании ACAP, следует рассмотреть существующие архитектуры и пояснить их предназначение [3] (см. рис. 2):
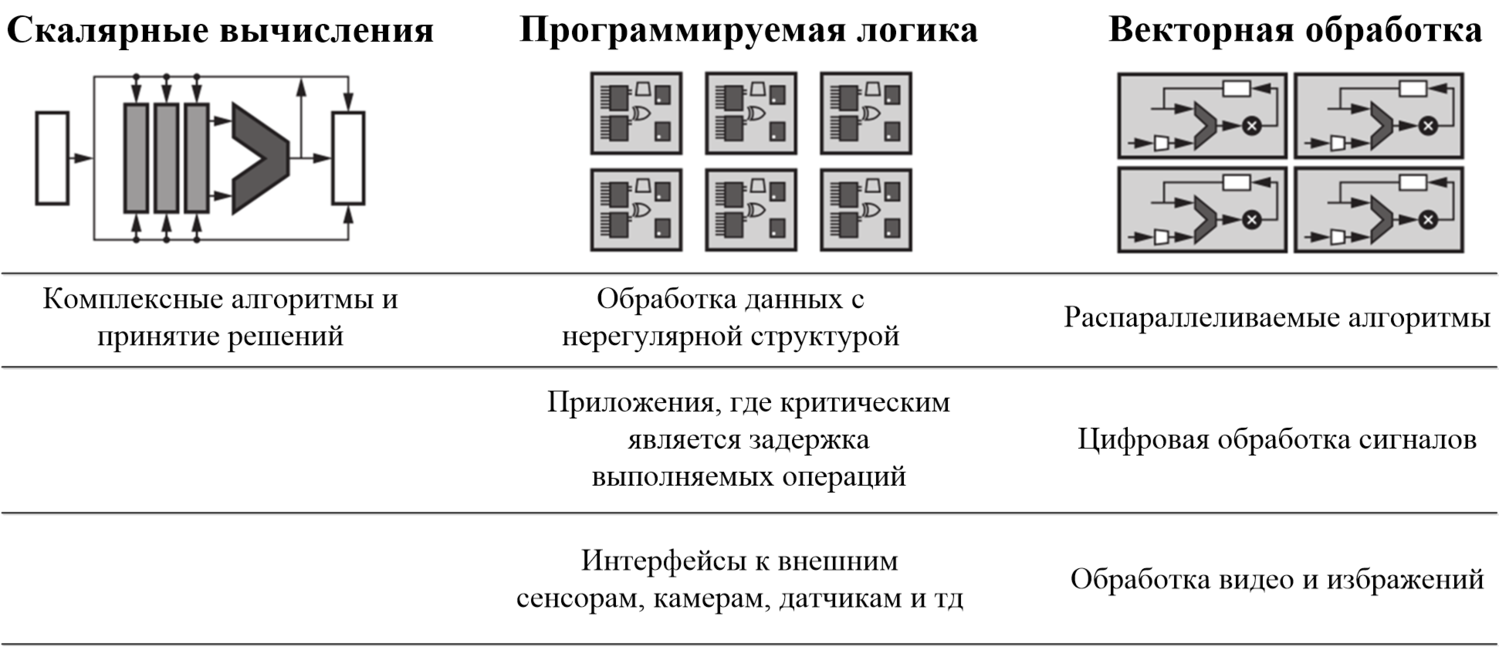
Рис. 2. Различные вычислительные архитектуры и решаемые с их помощью задачи
- Скалярные вычислительные элементы (CPU): эффективны для решения комплексных алгоритмов и последовательных задач принятия решений, но имеют ограниченный прирост производительности при масштабировании системы.
- Элементы векторной обработки (DSP – digital signal processor, GPU – graphics processor unit): наиболее эффективны в случае возможности распараллеливания решаемой задачи – однако теряют в производительности из-за негибкой иерархии памяти, т.е. наиболее узким местом системы является обмен данными с внешней памятью.
- Программируемая логика (FPGA): может быть сконфигурирована для решения конкретной задачи, что делает её наилучшим решением в приложениях, где критичным является задержка вычислений (например, системы помощи водителю) или имеется нерегулярная структура данных (например, вычисление генома). Однако традиционно узким местом таких систем является время необходимое для компиляции и имплементации кода, которое обычно составляет несколько часов, в то время как для других рассматриваемых архитектур этот процесс занимает считанные минуты.
Проанализировав все достоинства и недостатки вышеизложенных архитектур, Xilinx пришёл к выводу, что наилучшим является комплексное решение, объединяющее в себе все три архитектуры (см. рис. 3) – или адаптируемая платформа ускорения вычислений (ACAP).
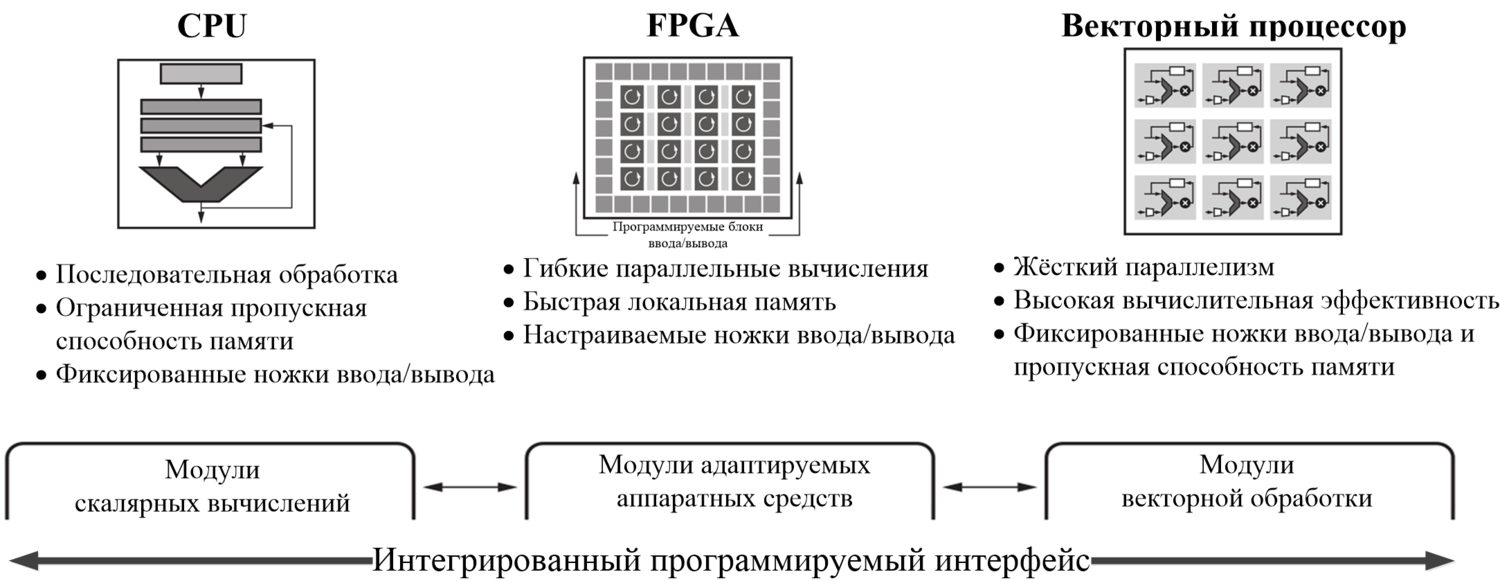
Рис. 3. Объединение в гетерогенную архитектуру
ACAP разработана таким образом, чтобы функционировать «из коробки», при этом не требуя от разработчика умений и знаний проектирования на языках RTL. По умолчанию ACAP ориентирована на проектирование с использованием высокоуровневых C-подобных языков и различных готовых фреймворков. Кристаллы с архитектурой VERSAL имеют встроенную оболочку (shell), которая включает технологии PCIe и CCIX с интегрированными контроллерами прямого доступа к памяти DMA, NoC и интегрированные контроллеры внешней памяти, скрывая от разработчиков необходимость работы на уровне RTL. Программирование может осуществляться на уровне фреймворков, например, для задач машинного обучения пользователь может непосредственно использовать Caffe или TensorFlow, также возможно использовать специализированные готовые библиотеки, например библиотеки фильтров для задач 5G. Традиционное проектирование на уровне RTL также возможно [3].
Три наиболее важных достоинства ACAP:
- Программируемость – способность «быстрого старта» разработки приложений с помощью специализированного программного обеспечения и фреймворков.
- Ускорение широкого спектра приложений от искусственного интеллекта и сетевых смарт-карт до беспилотных автомобилей и терабитных оптических сетей.
- Динамическая адаптируемая реконфигурация – способность реконфигурировать аппаратную часть кристалла (FPGA) под решение другой задачи в течение нескольких миллисекунд.
Аппаратное обеспечение платформы ACAP
ACAP представляет собой смесь нескольких систем: скалярной, адаптируемой и интеллектуальной, связанных между собой с помощью NoC – это сеть с огромной пропускной способностью в несколько Тбит/с (см. рис. 1).
Скалярная система построена на основе двухъядерного процессора ARM Cortex-A72, имеющего в 2 раза большую производительность на ядро, по сравнению с ARM Cortex-A53, используемого в кристаллах предыдущего поколения Xilinx. Сочетание усовершенствованной архитектуры процессора и технологического процесса FinFET 7 нм позволяет в 2 раза улучшить показатель DMIP/Вт по сравнению с технологией 16 нм. Сертифицированные по стандарту ASIL-C процессоры Cortex R5 из семейства UltraScale+™ перенесены на 7 нм техпроцесс с дополнительным уровнем безопасности и подходят для ответственных (safety) приложений.
Адаптивная система состоит из программируемой логики и ячеек памяти. Отличительной особенностью программируемой логики нового поколения является то, что её можно перепрограммировать для организации иерархии памяти, настроенной на конкретную вычислительную задачу. Такой подход позволит интеллектуальной системе достичь гораздо более высокой эффективности и большой пропускной способности памяти на единицу вычислений по сравнению с современными CPU и GPU.
Интеллектуальная система представляет собой набор модулей с поддержкой выполнения очень длинной машинной командой (very long instruction word – VLIW), обработкой множественных данный по принципу SIMD, которые соединены между собой с помощью интерконнектов, что позволяет достичь пропускной способности данных в сотни Тбит/с. Такая система обеспечивает повышение производительности в 5–10 раз в задачах цифровой обработки сигналов и машинного обучения [3].
Гетерогенные модули VERSAL ACAP обеспечивают оптимальное ускорение программных приложений независимо от типа приложения. Интеллектуальная система ускоряет решение задачи машинного обучения и классические алгоритмы цифровой обработки сигналов. Программируемая логика нового поколения внутри адаптируемой системы ускоряет параллелизуемые алгоритмы. Многоядерный процессор предоставляет исчерпывающие встроенные вычислительные ресурсы для остальных приложений.
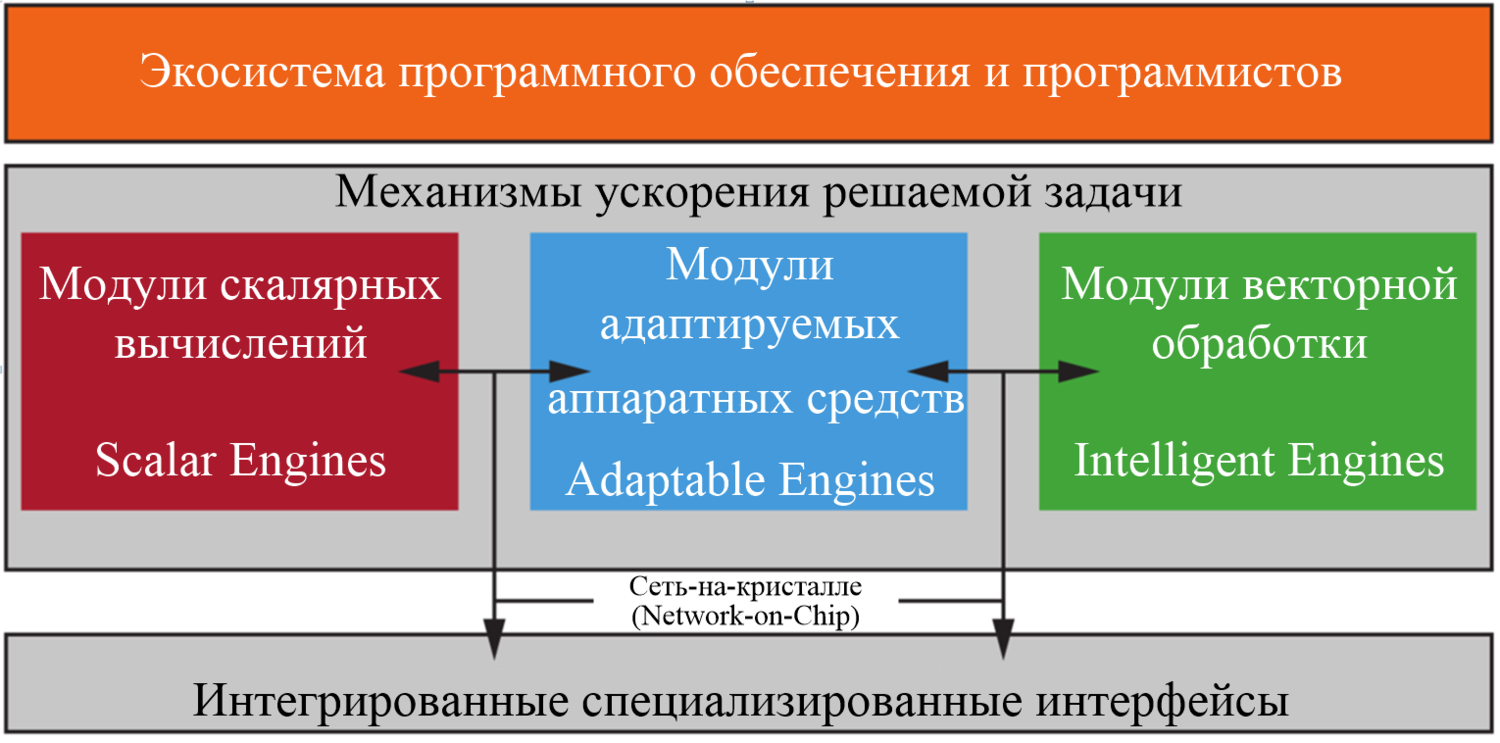
Рис. 4. VERSAL ACAP – концептуальная диаграмма
VERSAL спроектирован таким образом, чтобы его программирование осуществлялось без навыков программирования на уровне RTL (см. рис. 4, 5), что открывает новые возможности для специалистов из разных сфер:
- Учёные, работающие с Big Data и искусственным интеллектом, могут решать свои задачи с помощью стандартных фреймворков и ускорить получение результатов.
- Разработчики прикладных программ могут ускорить любое приложение, даже не имея опыта работы в низкоуровневом проектировании (RTL).
- Аппаратные разработчики (HW/RTL) могут продолжать использовать стандартные маршруты RTL проектирования с использованием Vivado® Design Suite, при этом уменьшая время разработки за счёт использования архитектуры VERSAL, готовых IP блоков и аппаратных решений.

Рис. 5. Концепция программирования архитектуры VERSAL
Специализированные аппаратные блоки
Наличие гибких программируемых интерфейсов позволяет получить доступ к компонентам, расположенным вне кристалла, включая стандартные интерфейсы для общения с внешним хост-процессором. В приложениях, относящихся к дата-центрам, программное приложение обычно расположено на стороне хост-процессора. Интерфейс, позволяющий подсоединить хост-процессор к программируемым ресурсам платформы VERSAL называется оболочкой (the shell). Встроенная оболочка включает интерфейсы CCIX (cache coherent interconnect for accelerators), PCIe Gen4x16, контроллеры DMA, кэш-когерентную память, встроенные контроллеры памяти.
NoC выступает в качестве связующей сети IP-модулей и аппаратных компонентов архитектуры. Это открывает возможность стандартизации и масштабирования аппаратного фреймворка, позволяя достичь эффективного обмена данными между компонентами гетерогенной архитектуры VERSAL [3].
Несмотря на то, что программируемая логика (FGPA) и векторные вычислители (DSP, GPU) имеют лучшие характеристики в вычислительном плане, чем типовые центральные процессоры, преимущество архитектуры ACAP заключается в том, что она объединяет все три типа вычислителей на одном кристалле, образуя тем самым жёстко-связанный гетерогенный вычислитель. И в данном случае может получиться так, что «1+1+1 будет больше 3», то есть эффект от одновременного использования различных типов вычислителей вместе будет больше чем от каждого по отдельности.
Показатели преимущества по ключевым сегментам рынка, достигаемые при применении ACAP VERSAL, приведены в таблице 1 [3].
Таблица 1. VERSAL ACAP и ключевые сегменты рынка
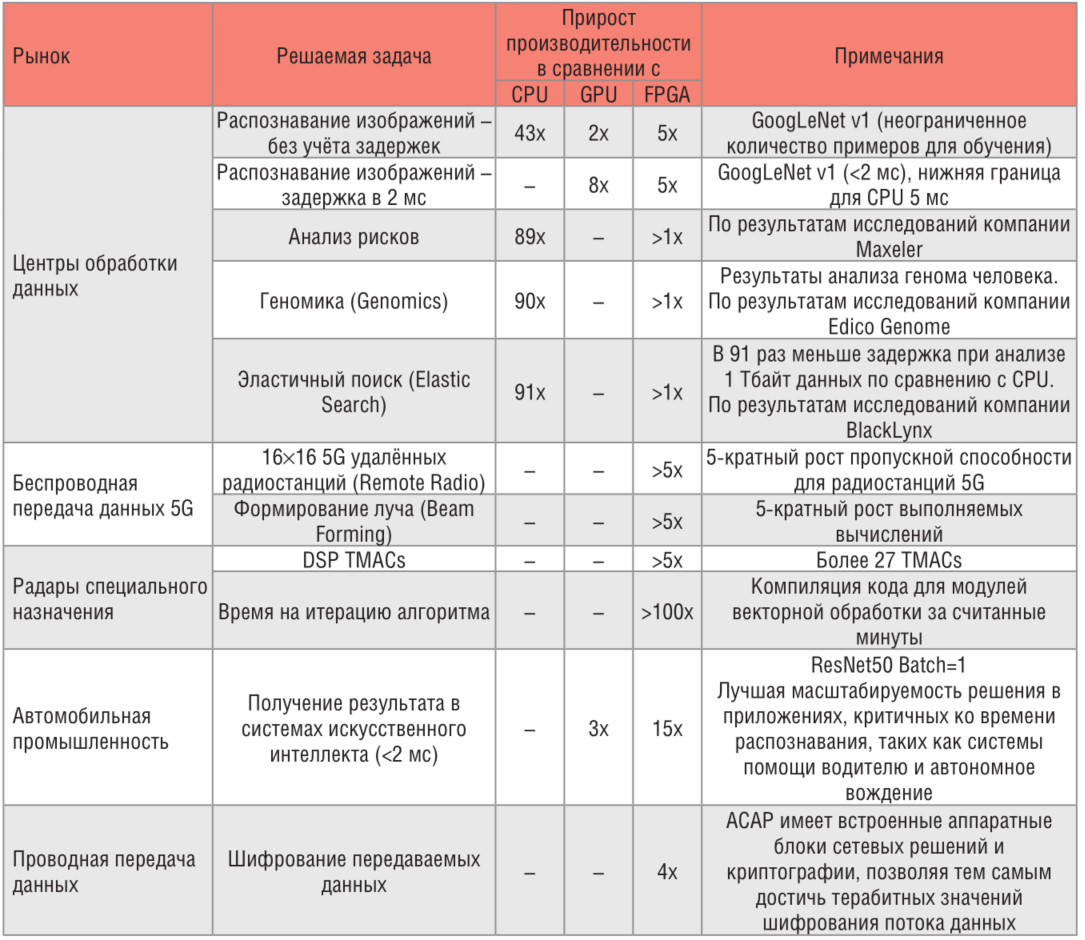
В настоящее время для ознакомления с архитектурой и особенностями доступны документы для двух серий: AI Core и Prime.
Данная серия [4] архитектуры VERSAL обладает наивысшими вычислительными показателями и минимальными задержками выполнения операций, позволяя получить лучшие результаты в задачах искусственного интеллекта и машинного обучения. Кристаллы этой серии оптимизированы для применения в облачных вычислениях, сетевых приложениях и автономных устройствах. В серии AI Core планируется 5 устройств, в которых будет:
- от 128 до 400 вычислительных блоков AI Engines;
- двухъядерный процессор ARM Cortex™-A72;
- двухъядерный процессор реального времени ARM Cortex-R5;
- 256 кбайт встроенной памяти с функцией коррекции ошибок ECC;
- более чем 1900 DSP-блоков, оптимизированных для вычислений с плавающей запятой с минимальной задержкой;
- более 1,9 миллиона системных логических ячеек;
- 130 Мбайт памяти UltraRAM;
- до 34 Мбайт блочной памяти RAM и до 28 Мбайт распределённой памяти;
- 32 Mбайт памяти для ускорителя, которая доступна непосредственно из любого модуля и является уникальной для устройств серии VERSAL AI.
Также будут доступны PCIe Gen4 x8 и x16, CCIX, трансиверы 32 Гбит/с, до 4-х контроллеров памяти DDR4, до 4-х Multirate Ethernet-контроллеров, 650 высокосортных входов/выходов для организации интерфейсов MIPI D-PHY, NAND, LVDS плюс 78 мультиплексируемых входа/выхода, соединённых с внешними компонентами и более чем 40 входов/выходов, поддерживающих напряжение до 3,3 В (High Density I/O). Все эти компоненты объединены сетью-на-кристалле NoC, которая имеет до 28 мастер/слейв портов с пропускной способностью в несколько Тбит/с. Технические параметры и производительность для данных различной точности приведены в таблицах 2 и 3 соответственно [5].
Основные преимущества серии AI Core
Улучшенные системные характеристики:
- Новый класс вычислительных модулей для векторных операций AI Engines более чем в 100 раз превосходит в вычислениях серверные процессоры.
- Настраиваемая иерархия памяти под конкретную вычислительную задачу, которая позволит избежать большой задержки обращения к памяти – наиболее узкого места многих вычислительных систем.
- Многоядерная процессорная система на базе ARM Cortex-A72 с двукратным приростом производительности по сравнению с предыдущей версией A53.
- Шина PCIe Gen4 с пропускной способностью 25 Гбит/с и поддержкой CCIX для кэш-когерентного соединения с хост-процессором.
- Одно устройство из серии AI Core способно заменить серверную стойку с самыми производительными на сегодня CPU.
- Динамическое переключение между решаемыми задачами для объединения нескольких ускорителей в один.
- Динамическое реконфигурирование частей кристалла за считанные миллисекунды для решения любых задач от обработки и распознавания изображений до решения научно-прикладных задач.
- рограммное обеспечение оптимизировано для задач глубокого и машинного обучения.
- Предварительно установленные интерфейсы («оболочка», shell) с повышенной безопасностью, легко интегрируемые в вычислительную инфраструктуру.
- Компиляция фреймворков за считанные минуты.
- Также новая серия AI Cores потребляет почти на 50% меньше мощности по сравнению с устройствами предыдущего поколения (при использовании новых функций).
Серия Prime [6] является основной серией среднего диапазона платформы VERSEL, применимой в нескольких сегментах рынка. Эти приложения включают разработку сетевого оборудования с пропускной способностью от 100 до 200 Гбит/с, центры обработки данных, коммуникационное тестовое оборудование. Устройства этой серии содержат трансиверы на 58 Гбит/c, оптимизированные блоки ввода/вывода и DDR, обеспечивая малую задержку и высокую производительность. Технические параметры и производительность для данных различной разрядности для серии Prime приведены в таблицах 4 и 5 соответственно [7].
Характеристики серии Prime:
- до 2-х миллионов системных логических ячеек;
- интегрированные Multirate MAC (Medium Access Control) c поддержкой 10/25/40/50 Гбит/c Ethernet с задержкой 1 нс для возможности применения в приложениях eCPRI и TSN;
- интегрированные высокопроизводительные многоканальные DMA-контроллеры;
- PCIe Gen4 c поддержкой CCIX (до 252 виртуальных функций);
- NoC с пропускной способностью более 1 Тбит/с;
- многоядерная процессорная система на базе ARM Cortex-A72 с двукратным приростом производительности по сравнению с предыдущей версией A53;
- многоядерный процессор реального времени ARM R5.
- Выигрыш почти в два раза в показателе производительность/ватт по сравнению с устройствами предыдущего поколения.
- Оптимизированные по потребляемой мощности трансиверы на 32 и 58 Гбит/c, поддержка PAM4.
- 3200 Мбит/с DDR4 и 4266 Мбит/с LPDDR4 с интегрированными DMA контроллерами.
- Экономичные высокоскоростные трансиверы на 25/50/100 Гбит/c для сетевых приложений и дата центров.
- Три рабочих напряжения позволяют выполнить настройку производительности и потребляемой мощности без ущерба производительности для конечного приложения.
- Корпус без крышки для улучшенного до 40% теплоотвода.
- Почти на 40% меньше потребляемой мощности по сравнению с устройствами предыдущего поколения (при использовании новых функций).
- Оптимизированные по потребляемой мощности трансиверы для приложений, в которых критична стоимость и потребляемая изделием мощность, таких как сетевые смарт-карты NIC, 5G коммутаторы (eCPRI) и виртуализация сетевых функций NFV.
- Оптимизированное программное обеспечение.
- Методология применения NoC.
- Предварительно интегрированные интерфейсы.
Планы Xilinx по выпуску кристаллов
Как следует из презентации (см. рис. 6), Xilinx планирует выпустить первые кристаллы серий AI Core и Prime во втором квартале 2019 года. Кристаллов следующих семейств следует ожидать не ранее 2020 года, а именно в первом квартале 2020 года планируется выход на рынок кристаллов серий Premium и AI Edge, во втором квартале 2020 года кристаллов серии AI RF и заключительным планируется выход серии с интегрированной высокопроизводительной памятью HBM Series, однако это случится по планам только во втором квартале 2021 года [2].
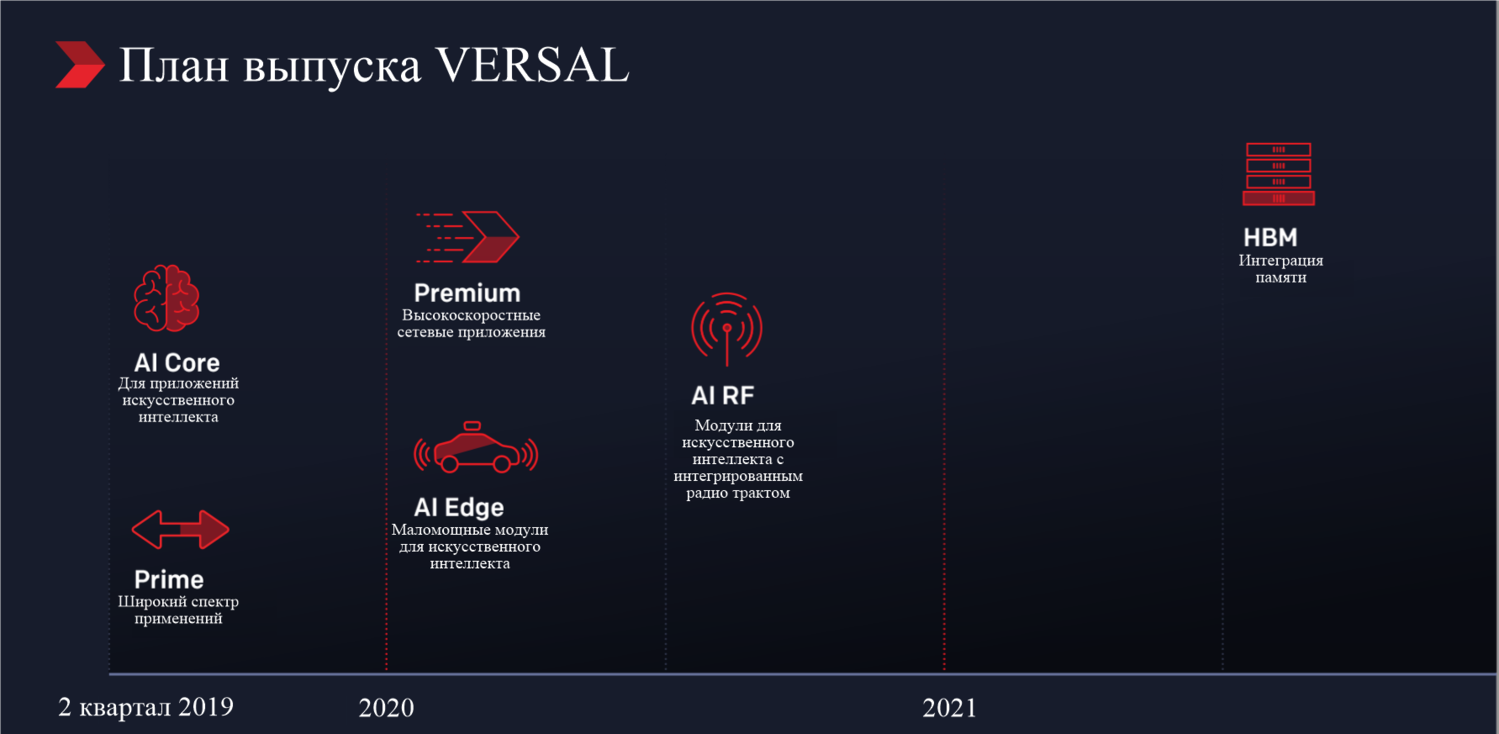
Рис. 6. План выпуска кристаллов с архитектурой VERSAL
Для того чтобы не пропустить выход новых анонсов, новостей и документов по архитектуре VERSAL, Xilinx предлагает подписку на новые обновления информации по VERSAL [8].
1. Versal.
2. Versal Presentation.
3. WP505. Versal: The First Adaptive Compute Acceleration Platform (ACAP). Xilinx. 2018.
4. Versal AI Core Series. .
5. XMP452 – Versal AI Core Series Product Selection Guide (ver1.0.1). Xilinx inc. Oct. 2018.
6. Versal Prime Series.
7. XMP453 – Versal™ Prime Series Product Selection Guide (ver1.0.1). Xilinx inc. Oct. 2018.
8. Versal Stay Informed. .