Тензорные секции в ПЛИС




Мысли на тему эволюции ПЛИС, которые я нашел в одном из блогов на просторах интернета
 Тензорные секции относятся к машинному обучению так же, как секции DSP относятся к цифровой обработке сигналов.
Тензорные секции относятся к машинному обучению так же, как секции DSP относятся к цифровой обработке сигналов.
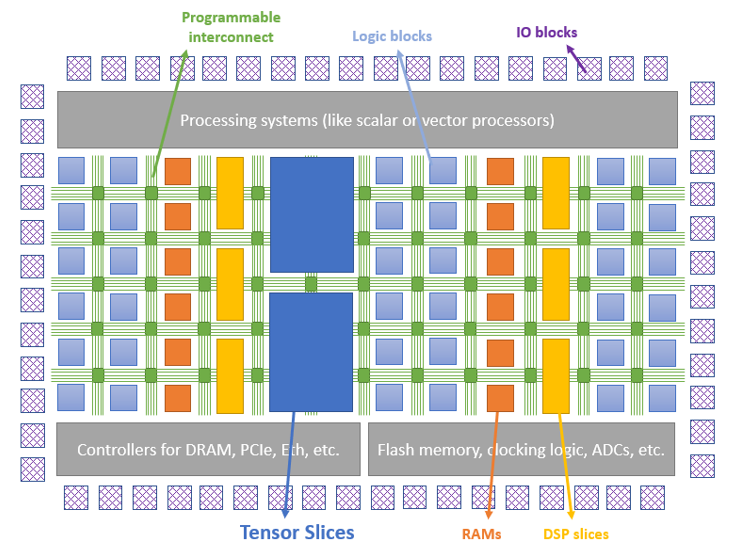
Когда появились ПЛИС, они были очень однородными. Они содержали логические блоки, соединенные через матрицу маршрутизации. Однако в какой-то момент стало понятно, что существует много общих операций (таких как умножение и MAC), которые присутствуют в приложениях, для которых использовались ПЛИС. Это было особенно верно для приложений ЦОС, которые были и являются очень распространенным вариантом использования ПЛИС.
Итак, блоки умножения и умножения с накоплением MAC были добавлены в структуру FPGA. Они были названы "аппаратными / жесткими / hard" блоками, потому что они выполняют только несколько конкретных задач, и выполняют их хорошо (в отличие от логических блоков, которые называются "мягкими / soft" блоками, потому что они могут реализовать практически любую цифровую логику). Блоки оперативной памяти также были добавлены структуру FPGA для хранения данных (хотя я думаю, что это произошло до добавления секций DSP). ПЛИС постепенно становились все более и более неоднородными за счет добавления в их структуру все более разнообразных "аппаратных" блоков.
 С преобладанием направлений ИИ, таких как глубокое и машинное обучение (DL/ML) ПЛИС снова находятся на интересном этапе развития. ПЛИС используются для очень многих приложений DL, как в облаке, так и на периферии (edge). В таких приложениях тензорные/матричные операции являются сердцем DL. Таким образом, кажется логичным, что добавление жестких аппаратных блоков, специализирующихся на тензорных/матричных операциях, в ПЛИС может помочь сделать ПЛИС более эффективными в ускорении приложений DL.
С преобладанием направлений ИИ, таких как глубокое и машинное обучение (DL/ML) ПЛИС снова находятся на интересном этапе развития. ПЛИС используются для очень многих приложений DL, как в облаке, так и на периферии (edge). В таких приложениях тензорные/матричные операции являются сердцем DL. Таким образом, кажется логичным, что добавление жестких аппаратных блоков, специализирующихся на тензорных/матричных операциях, в ПЛИС может помочь сделать ПЛИС более эффективными в ускорении приложений DL.
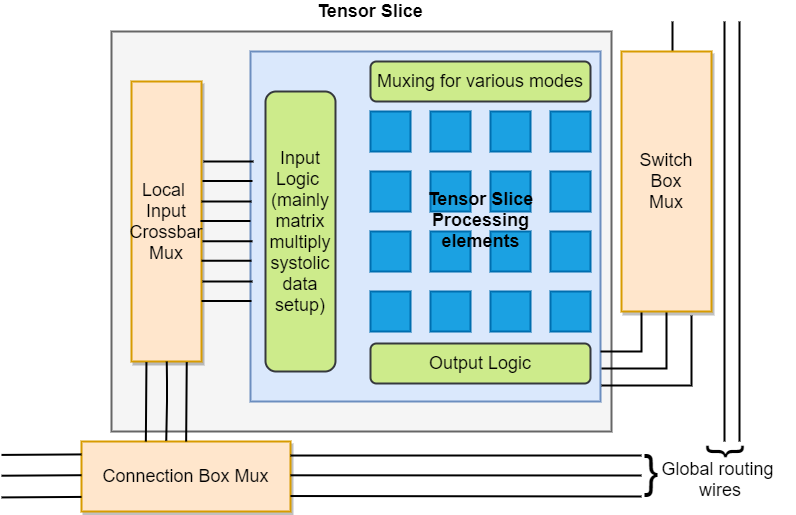
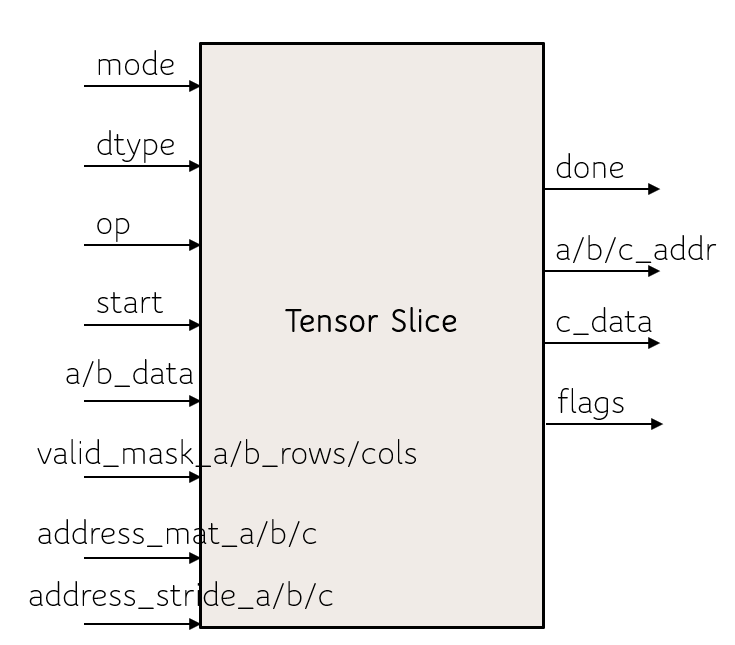 Мы предложили добавить в ПЛИС блоки, называемые тензорными секциями. Эти блоки поддерживают матричное умножение и поэлементное сложение, вычитание и умножение матриц для различных размеров и точности (в частности, 4x4 fp16 и 8x8 int8). Секции имеют в своей основе массив элементов систолической обработки, как показано на изображении слева. Добавление тензорных секций увеличивает плотность вычислений ПЛИС (больше TMAC/секунду/площадь).
Мы предложили добавить в ПЛИС блоки, называемые тензорными секциями. Эти блоки поддерживают матричное умножение и поэлементное сложение, вычитание и умножение матриц для различных размеров и точности (в частности, 4x4 fp16 и 8x8 int8). Секции имеют в своей основе массив элементов систолической обработки, как показано на изображении слева. Добавление тензорных секций увеличивает плотность вычислений ПЛИС (больше TMAC/секунду/площадь).
Мы наблюдали увеличение средней частоты в 2,45 раза, уменьшение средней площади до 0,4 раза и уменьшение средней длины проводов маршрутизации до 0,4 раза в нескольких тестах ML. Мы не наблюдали заметного снижения производительности тестов, не связанных с ML (для случаев, когда мы тратили до 10% площади ПЛИС на тензорные секции).
Интересной частью этого исследования было то, как выполнить оценку архитектуры FPGA (Особая благодарность доктору Вону Бетцу из Университета Торонто за его руководство). Мы попытались довольно хорошо объяснить это в статье. Он использует в основном инструменты с открытым исходным кодом! Прочитайте статью, если вас интересует этот аспект (ссылка в следующем параграфе).
Наши первоначальные исследования в этой области начались еще в 2019 году, когда мы впервые предложили добавить блоки матричных умножителей в ПЛИС. Эта работа была выбрана в качестве плаката в ISFPGA'20 и была опубликована в качестве статьи под названием Hamamu на ASAP'20. Мы внесли множество улучшений и новых функции в Тензорные секции и переработали стратегию оценки, - и эта работа была опубликована в качестве статьи под названием " Tensor Slices" на ISFPGA'21.
Intel недавно (в июле 2020 года) представила новую ПЛИС под названием Stratix NX. Эти ПЛИС имеют блок, называемый тензорным блоком. Эти блоки очень похожи на Тензорный секции, хотя они имеют меньшую вычислительную пропускную способность (30 int 8 MAC вместо 64 для тензорной секции). Большим преимуществом этих блоков является то, что они были заменой секций DSP и не нарушали структуру маршрутизации базового устройства Stratix. Intel, выпустившая эти блоки примерно в то же время, когда мы работали над предложением добавить тензорные секции, убеждает нас в том, что наши исследования находятся на правильном пути. Я надеюсь, что пользователи воспользуются преимуществами тензорных блоков для ускорения приложений DL.
| Материал опубликован с разрешения автора Aman Arora - Research assistant at The University of Texas at Austin Ссылка на оригинал и персональный сайт автора |