Искусство отладки FPGA: как сократить срок тестирования за счет грамотной разработки




Примеры FPGA-проектов на базе Nvidia Jetson, Zynq UltraScale+ и Xilinx KRIA
Давайте попробуем оптимизировать самый времязатратный этап разработки устройств на базе ПЛИС — отладку прошивки. В этой статье мы расскажем о принципе 20/80 при планировании времени, рассмотрим инструменты для отладки FPGA, вспомним Гордона Мура и Уинстона Черчилля (да-да), затронем отладку сложных распределенных систем и внешних интерфейсов, а в конце — разберемся с типичными ошибками и поделимся полезными практическими советами.
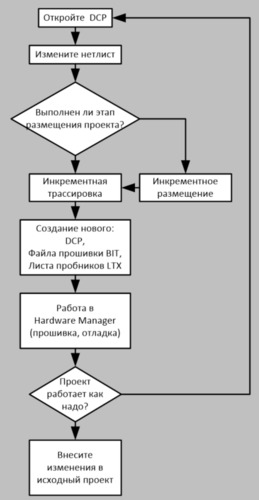
Для начала рассмотрим типовой цикл программирования и моделирования FPGA-прошивки:

Все знакомы с классическим итерационным циклом разработки прошивки:
- Разработка FPGA-прошивки, а по факту — использование стандартных блоков и собственно разработка одного-двух специфических блоков.
- Моделирование — проверка базовой функциональности устройства.
- Синтез.
- Имплементация.
- Прошивка ПЛИС.
- Тестирование, которое чаще всего превращается в отладку.
После каждого из первых трех этапов, в том числе и после синтеза, в классическом цикле разработки предусмотрен этап моделирования.
На практике моделирование синтезированного проекта — это по сути проверка корректности работы синтезатора, то есть на этом этапе мы не можем выявить для себя что-то новое. В целом результат поведенческого моделирования не должен отличаться от моделирования после этапа синтеза, если синтезатор правильно понял код на одном из языков описания аппаратуры.
Моделирование после стадии имплементации позволит проверить, насколько дизайн выполняет заданную функцию с учетом реальных таймингов и раскладки внутри кристалла. Если уделить достаточно времени моделированию RTL-описания, то можно будет сэкономить времени на этапе отладки.
Принцип 20/80 для разработки и отладки FPGA-проекта
Как показывает наш опыт и опыт коллег по FPGA-разработке, моделирование и отладка обычно занимают бо́льшую часть времени на проекте. Можно ориентироваться на закон Парето: порядка 20% времени уходит на саму разработку, написание кода, реализацию верхнего уровня дизайна в виде блок-диаграммы и порядка 80% — на тестирование, отладку и поддержку.


Диаграмма «Распределение времени на разработку и отладку FPGA-проекта»
С чем связано такое суровое распределение на 20/80?
- Отчасти это обусловлено самим итерационным процессом разработки. Каждая итерация занимает много времени, большие проекты требуют много времени на этапе пересборки. Например, час-полтора минимум для типового проекта для ПЛИС Xilinx (такой как Xilinx Zynq UltraScale+). Есть и более крупные проекты, которые могут собираться гораздо дольше.
- Для успешного завершения процесса отладки от FPGA-разработчика требуется не только навык написания прошивки на одном из HDL-языков или создания его блок-дизайна, но еще и навыки программирования на других языках. Например, Си и Python для написания некоторых тестовых скриптов. Также может понадобиться и такой скриптовый язык как Tcl.
А теперь давайте разбираться с тем, как сократить этап отладки, который стоит в нашем рабочем процессе на последнем месте, но занимает основную часть времени проекта.
Типы инструментов для отладки FPGA
У программистов — высокоуровневых или embedded — для отладки есть большой инструментарий: дебаггеры, возможность пошагово исполнять программный код, широкие возможности по логированию работы программы. А вот у FPGA-разработчиков для отладки своих ПЛИС набор инструментов ограничен. Итак, что у нас есть:
- Измерительное оборудование: осциллографы и логические анализаторы. Эти инструменты позволяют понять, что происходит за пределами ПЛИС, но не дают заглянуть внутрь. С их помощью можно отладить внешний интерфейс и посмотреть, как ПЛИС взаимодействует с внешним миром.
- Встроенные средства отладки позволяют заглянуть внутрь ПЛИС. Такие инструменты есть у всех популярных производителей FPGA и называются они по-разному: у самого известного производителя, Xilinx, – это ChipScope, у Intel (ex. Altera) – SignalTap, у Microchip (ex. Microsemi) – продукт от Synopsys, который называется Identify RTL Debugger. Встроенные отладчики схожи по функциям.

Примеры встроенных отладчиков компаний Xilinx, Intel (ex. Altera) и Microchip (ex. Microsemi)
Ограничения встроенных отладчиков
Разрушающий метод контроля
При использовании встроенных отладчиков важно помнить, что использование ChipScope, SignalTap и Identify RTL Debugger — это разрушающий метод контроля. При добавлении отладчика внутрь FPGA-прошивки мы нарушаем логику ее работы: занимаем часть ресурсов ПЛИС, за счет этого меняется раскладка проекта внутри кристалла, меняются временные параметры, и в результате мы получаем не на тот продукт, который был до момента добавления отладчика.
Выбор «Отсчеты vs сигналы»
Встроенный отладчик использует для своей работы ресурсы ПЛИС — блочную память, ресурсы памяти, поэтому перед нами возникает необходимость выбора: мы можем посмотреть много отсчетов, но при этом будем видеть мало сигналов, ИЛИ мы хотим просмотреть много сигналов, но при этом сократится количество отсчетов. Перед разработчиком FPGA всегда стоит проблема выбора: отсчеты или сигналы. Приходится определять оптимальный набор наблюдаемых сигналов и оптимальное время наблюдения.
Простой пример: мы хотим посмотреть 4096 отсчетов на частоте 200 МГц, это всего 20 мкс реального времени. А за 20 мкс реального времени иногда можно увидеть часть процесса, который мы пытаемся отладить. И если мы при этом хотим пронаблюдать пару 512 разрядных шин, это потребует 4 Мбита памяти ПЛИС, что для некоторых кристаллов составляет большой процент от ее общего доступного объема.
Пошаговое исполнение
Есть еще одна интересная фишка, но она доступна только в отладчике Synopsys для ПЛИС Microchip (ex. Microsemi) — так называемое пошаговое исполнение, к которому привыкли разработчики высокоуровневого ПО. Эта фича заявлена как прогрессивное решение, хотя сам отладчик далеко не новый.
Отладчик Synopsys позволяет остановить исполнение прошивки в ПЛИС в определенный момент и дальше продолжать исполнение кода такт за тактом. Интересное решение, но у отлаженного проекта в этом случае появляется масса ограничений:
- На практике более-менее качественно можно отлаживать проект, состоящий из одного домена синхронизации. Для большого проекта такая фишка уже не актуальна.
- Если в проекте есть внешние интерфейсы, которые привязаны к реальному времени (даже самый банальный UART), то в момент остановки исполнения, естественно, мы нарушаем всю коммуникацию с внешним устройством и после одной такой остановки дальнейшее пошаговое исполнение теряет смысл.
Вывод: любопытный инструмент, но нам пока не удалось найти ему качественное применение на практике.
Мур, Черчилль и правила отладки FPGA

Прежде чем отправиться дальше, хотим поделиться двумя полезными правилами, которые помогут спланировать этап отладки FPGA и не отчаяться в процессе. :-) Первое эмпирическое правило напоминает всем знакомый закон Мура: «Каждая последующая ошибка находится в два раза дольше предыдущей». Эта информация полезна для оценки времени, которое необходимо заложить для отладки и развития проекта.
Чем обусловлен такой рост времязатрат? Каждая последующая ошибка возникает при гораздо более сложных начальных условиях, а для повторения этих условий требуется гораздо больше времени. Наш опыт показывает, что этот принцип работает: одну ошибку ищем в течение дня, следующую ошибку будем искать как минимум в течение двух дней.
Второе эмпирическое правило — это видоизмененное высказывание, которое приписывают Уинстону Черчиллю. Он якобы говорил, что успех — это умение двигаться от одной неудачи к другой, не теряя энтузиазма.
«Для FPGA-разработчика отладка – это умение двигаться от одной ошибки к другой, не теряя энтузиазма.»
Последняя часть высказывания про энтузиазм — самая важная, потому что отладка устройства на базе ПЛИС — это постоянная эмоциональная борьба с прошивкой. После каждой твоей победы прошивка как бы говорит: «Нет, товарищ, ты рано расслабился, у меня есть еще одна ошибка, и ты будешь ее искать в два раза дольше, чем предыдущую».
Отладка распределенных FPGA-систем
При отладке простых систем с одной платой и одной ПЛИС сложности есть, но они решаемы, а вот отладка распределенных систем — это другое дело. Под распределенными системами мы понимаем два типа систем: гетерогенные и гомогенные.
Для гетерогенных систем правила отладки примерно такие же: каждая плата выполняет свою функцию, мы отлаживаем каждую в отдельности, а затем — в составе системы.
А теперь пример с гомогенными системами: рассмотрим VPX-модуль на 12 слотов. Давайте представим, что туда вставлены 10 слотов с FPGA, 1 слот с коммутатором PCI Express и 1 слот — с CPU, который все эти данные агрегирует, обрабатывает и передает дальше. Такая система по своей структуре является гомогенной, потому что каждый модуль выполняет одинаковую функцию.

На фото слева — VPX-система на 12 слотов, справа — ПЛИС-модуль, который в нее вставляется
В случае отладки гомогенных системы мы сталкиваемся с эффектом масштабирования: если мы отладили одну плату, прогнали все тесты и видим, что она работает, то с учетом эффекта масштабирования это не гарантирует, что так будет работать система на двух платах. Когда мы отладили систему на двух, это не гарантирует, что так будут работать все три платы и т. д. — пока мы не заставим систему корректно работать на всем массиве нужных плат.
Сложности при отладке распределенных систем
1. Невозможность подключиться ко всем ПЛИС одновременно.Если у нас большое число FPGA-устройств, мы не можем одновременно подключиться к встроенному отладчику через JTAG. Первая проблема: у вас может не оказаться 10 компьютеров для подключения к каждому модулю. Вторая проблема характерна для VPX-систем, в них FPGA-устройства соединены в одну JTAG-цепочку и, соответственно, вы просто технически не можете подключиться ко всем ПЛИС одновременно.
2. Недетерминированность возникновения ошибки, т. е. ошибка может равновероятно возникнуть в любом из 10 или N модулей. Это существенно осложняет процесс отладки. Во-первых, необходимо повторить ситуацию, вызвавшую ошибку. Во-вторых, мы должны взвести встроенный отладчик на ту плату, на которой надеемся увидеть ту самую ошибку, т. е. здесь у нас нет никаких инструментов, кроме везения и многократного запуска тестов, пока ошибка не возникнет там, где мы ее ждем.
3. Сложный критерий детектирования ошибки — третья сложность, с которой мы сталкиваемся при отладке сложных распределенных FPGA-систем и не только. Часто ошибку невозможно детектировать внутри ПЛИС (с точки зрения ПЛИС данные идут корректные), но когда мы эти данные передаем дальше на обработку, например, сигнальному процессору, он может детектировать в них ошибку. Даже если он с помощью каких-то сигналов обратной связи сообщит об этом ПЛИС (запустим в этот момент встроенный отладчик), то мы не увидим ошибки, потому что событие произошло достаточно давно на временной шкале в прошлом, и причину возникновения ошибки мы определить не сможем.
Как быть? В этом случае при отладке можно добавить внутрь основного устройства дополнительные блоки, которые контролируют входные данные. И порой сложность этих контролирующих блоков может сравниться со сложностью блоков, которые мы разрабатываем для имплементации в FPGA.
Отладка внешних интерфейсов
Любое FPGA-устройство так или иначе взаимодействует с внешним миром, поэтому мы не можем обойти стороной отладку внешних интерфейсов.
Блоки прошивки FPGA взаимодействуют между собой и со сторонними устройствами, ведь если блок не имеет внешних связей, то на этапе синтеза он будет абсолютно резонно удален из проекта — для оптимизации.

Анализатор PCIe протокола LeCroy (очень дорогое оборудование, облегчает отладку в разы)
В рамках идеологии блочного дизайна блоки взаимодействуют с помощью стандартных интерфейсов: для Xilinx — это AXI Memory mapped и AXI Stream, для Intel FPGA это будут похожие интерфейсы Avalon MM и Avalon Stream, также используется стандартная шина APB. С точки зрения отладки, это достаточно простые интерфейсы с ограниченным числом состояний и управляющих сигналов, поэтому серьезных проблем возникнуть не должно. Тем более у некоторых производителей для нее есть готовые решения: например, у Xilinx есть специализированные блоки, которые позволяют на лету проверять корректность протокола и детектировать ошибки на шине. Благодаря такому блоку можно зафиксировать момент ошибки, а затем при помощи встроенного отладчика посмотреть, что к этому привело.
Совсем иначе дело обстоит, когда один из интерфейсов используется в качестве транспорта для более высокоуровневого протокола. Например, низкоуровневое ядро PCI Express, которое работает на уровне TLP-пакетов и в качестве транспорта для передачи этих пакетов использует стримовый интерфейс AXI. AXI Stream — это стандартный интерфейс, мы понимаем, как он работает, но у нас нет возможности его отлаживать и следить за корректным формированием TLP-пакетов, которые мы передаем через AXI Stream в ядро PCI Express.
При программировании и последующей отладке таких блоков разработчик ПЛИС сталкивается с проблемами, которые невозможно решить без применения специализированного дорогостоящего оборудования (в случае с PCI Express это будет анализатор протокола PCI Express). Без такого оборудования отладка превращается в работу с черным ящиком. Максимум, что вам доступно – это проверка соблюдения требований интерфейса AXI Stream.
Поэтому если в проекте предстоит работа с такими интерфейсами, как PCI Express, 10/100G Ethernet или боле специфическими интерфейсами типа Infiniband, то при планировании проекта нужно учитывать, что на этапе отладки понадобятся соответствующие анализаторы, которые существенно упростят процесс работы. В результате тот же контроллер PCI Express перестанет быть черным ящиком, потому что мы сможем проанализировать поведение шины PCIe.
Если у нас нет доступа к специальному оборудованию для анализа и отладки, можно использовать поведенческие модели. Например, модель для контроллера PCI Express. Однако такая модель позволит нам получить лишь малый процент покрытия всех возможных ситуаций, с которыми ваше разрабатываемое устройство столкнется в реальной жизни. При попытке обеспечить больший процент покрытия моделирование может затянуться на неопределенное время, а проект не будет реализован.
Итак, вот три проблемы, с которыми сталкиваются FPGA-разработчики при отладке внешних интерфейсов:
1. Невозможность корректировки внешних интерфейсов
2. Необходимость использовать дорогостоящее оборудование для отладки:
- Анализаторы PCIe и 10/100G Ethernet
- Осциллографы 10—25 Гб/с с функцией анализа трафика
3. Модели черных ящиков не покроют 100% функциональности, особенно в части real-time
Три типичные ошибки процесса отладки FPGA
А теперь рассмотрим типичные ошибки на этапе отладки. Если вам удастся их избежать, вы сэкономите массу проектного времени.
Ошибка №1. Внесение двух и более исправлений за одну сборку
Учитывая, что сборка проекта может занимать несколько часов (а то и сутки), то возникает соблазн исправить сразу несколько замеченных ошибок. Но, как показывает практика, особенно в части сложных проектов, попытка сделать два и более исправления за раз чаще приводит к тому, что поведение отлаживаемой системы становиться еще более непредсказуемым, чем до внесения исправлений. Это происходит из-за сложной логической связанности — как между блоками, так и внутри блока. В результате приходится откатываться назад и последовательно проверять одно исправление за другим.
Решение этой проблемы достаточно простое: несмотря на длительное время пересборки проекта необходимо двигаться step by step – одно исправление, затем сборка и проверка, следующее исправление — снова сборка и проверка и т. д. Так вы сэкономите больше времени и усилий.
Ошибка №2. Ложная уверенность в верности алгоритма и работоспособности блока на основе анализа кода
Как это происходит? Разработчик смотрит на код, понимает, как он должен исполняться, и даже не пытается в это место добавлять встроенные отладчики, чтобы смотреть, что там происходит, «ведь по коду же видно, что все должно работать».
Возьмем классическую ошибку: различная разрядность шин. Если два сигнала разной разрядности попытаться сравнить в логическом операторе типа if в языке VHDL, то с точки зрения синтаксиса и визуально все будет выглядеть нормально, однако синтезатор это сравнение преобразует в вечное false и, соответственно, алгоритм работать не будет.
С аналогичной ошибкой мы столкнемся в языке Verilog, где можно вольно назначать один сигнал другому без контроля разрядности. При назначении сигнала большей разрядности сигналу меньшей разрядности мы потеряем часть значащих битов, хотя с точки зрения анализа кода будет корректно записанное логическое условие в первом случае и не менее корректное присвоение сигналов во втором случае.
Решение: при отладке, если есть возможность и ресурсы памяти позволяют, необходимо выводить в отладчик все сигналы, которые так или иначе участвуют в логическом условии, потому что даже, казалось бы, очевидные вещи могут приводить к некорректному поведению блока.
Ошибка №3. Перекладывание проблемы на блок коллеги или внешние микросхемы
Так могут поступать не только новички, но и опытные разработчики, которые исходят из предположения, что ошибка возникла не у них, а в блоке коллеги или даже в стандартном ядра или внешней микросхеме, с которой FPGA обменивается данными.
Надо признать, что ошибки случаются и в стандартных блоках, и даже в серийных микросхемах, и большая их часть задокументирована.
Решение: несмотря на то, что даже в стандартном ядре Xilinx может быть ошибка, нужно руководствоваться правилом «презумпции виновности», то есть исходить из предположения, что ошибка все-таки возникла в нашем блоке, а не в стандартном IP-ядре, например, AXI4 Interconnect, который по какой-то причине заблокировал транзакцию. Конечно, дополнительное письмо в службу техподдержки вендора блока лишним не будет.
Практические рекомендации
Ну и, наконец, рассмотрим список из восьми практических рекомендаций, который сделает процесс программирования ПЛИС более-менее управляемым.
1. Счетчики ошибок. Добавляйте их везде, где это возможно. Ошибки контрольных сумм, ошибки доступа, протокольные ошибки. Например: видим ошибку CRC — заводим счетчик ошибок CRC, замечаем появление некорректных данных в пакете — учитываем их тоже.
2. Счетчики статистики: счетчики данных, счетчики пакетов, счетчики запросов. Все блоки так или иначе обрабатывают данные — входные или выходные. Очень полезно поставить счетчик, чтобы видеть, сколько пришло на вход и сколько передано на выход.Если это пакетные данные, то считаем количество пакетов, если пакетам предшествует какой-то запрос (handshake) — считаем, сколько этих запросов было. На этапе отладки счетчики помогут определить, где потерялись данные в длинной цепочке из нескольких блоков.
3. Детектирование «невозможных» состояний и ситуаций. Почему невозможность взята в кавычки? Потому что в увлекательном мире ПЛИС нет ничего невозможного. :-) Может возникнуть любая ситуация, и к ней нужно всегда быть готовым, т.е. детектировать ее. Пусть это будет флаг, который показывает, что ваше устройство было в том состоянии, которое не предусмотрено спецификацией. И, когда мы получим готовое устройство, которое внезапно зависло, считывая эти флаги, увидим, что такая ситуация все-таки возникла и ее нужно корректно обработать.
4. Обработка всех сигналов ошибок. Если от сторонних блоков или интерфейсов в ваш блок приходят сигналы ошибки, их нужно обрабатывать, даже если они кажутся маловероятными или невозможными. Как минимум – все сигналы ошибок нужно фиксировать, чтобы определить причину проблемы, когда устройство перестанет работать или его поведение станет непредсказуемым.
Для примера вернемся к нашему контроллеру PCI Express: почему нужно обрабатывать такую ошибку, как потеря линка? Вероятность того, что endpoint, который коммуницирует с root-комплексом, вдруг потеряет линк, стремится к нулю, но если такая ситуация возникнет, мы должны знать, что она была.
5. Анализ флагов FULL / EMPTY и ситуаций UNDERFLOW / OVERFLOW
Эта рекомендация касается всеми любимого компонента в мире ПЛИС – FIFO (first in, first out). Это базовый элемент цифровой схемотехники, который используется для передачи данных из одного домена синхронизации в другой, для сглаживания разницы в скоростях между приемником и передатчиком, ну и по прямому назначению – для буферизации.
Для отладки полезно добавить логику, которая будет детектировать ситуации чтения из пустого буфера (underflow) и записи в переполненный (overflow). Так мы оперативно обнаружим место, где теряются данные, или, наоборот, — появляются из ниоткуда
6. Обеспечение доступа к состояниям FSM
Шестой пункт рекомендаций касается другого важного элемента цифровой схемотехники ПЛИС – конечных автоматов. Именно они позволяют в максимально наглядной форме описать логику устройства, например, парсеры пакетов, контроллеры интерфейсов AXI MM и многое другое. Доступ к состояниям автоматов позволяет понять, в каком состоянии зависло устройство и какого сигнала ждет, чтобы перейти из одного состояния в другое.

LTSSM — link training and status state machine
Изображённый на этой схеме конечный автомат – это автомат инициализации линка PCI express (LTSSM). И практически все ядра PCIe позволяют вывести состояние этого автомата за пределы ядра, так что этим требованием пользуются даже крупные вендоры, в частности, Xilinx и Altera.
7. Чтение документации «от корки до корки»
Это очень скучная рекомендация, но крайне полезная. Если на интерфейс или ядро, с которым вы работаете, есть документация (а она должна быть), читайте ее целиком. Да, совет может показаться странным, потому что на некоторые ядра документация занимает не одну сотню страниц. Вы потратите на это время, но с большой вероятностью это сэкономит гораздо больше времени, потому что даже стандартные интерфейсы, которые используются в тех или иных ядрах, не всегда работают так, как мы себе представляем.
Например, возьмем ядро PCI Express, работающее на уровне TLP-пакетов. Читаем документацию и видим, что в качестве интерфейса взаимодействия с пользователем задействован AXI Stream. Хочется пролистать этот раздел, ведь мы и так знаем, как работает и за что отвечают сигналы интерфейса AXI Stream. Но, в случае с ядром PCIe логика hand-shake-сигналов отличается от стандарта AXI Stream (в частности, у компании Xilinx). Если это не учесть, можно очень долго искать ошибку — особенно, не зная, где ее искать.
8. Применение автоматических синтезаторов HLS, Simulink (где возможно)
Ну и, наконец, последнее: применяйте по возможности автоматические синтезаторы. Например, среду HLS, которая позволяет реализовать вашу логику на языке С / С++. Или продукт Simulink, который позволяет реализовать логику FPGA на базе огромного набора стандартных библиотечных компонентов, а потом нажатием одной кнопки синтезировать из этого описание — HDL-код. Да, этот код будет нечитаемым с точки зрения разработчика. Очевидно, что написанное на HLS или реализованное в Simulink требует высокоуровневой поведенческой верификации и моделирования, но можно быть уверенным в том, что сгенерированный HDL-код, несмотря на свою нечитаемость, будет работать в ПЛИС.
В заключение отметим важный аспект: рекомендация «обеспечить доступ» к различным счетчикам и состояниям внутри ПЛИС, подразумевает разные варианты реализации:
1. Можно добавить к заведенным переменным встроенный отладчик типа Chipscope. Но бывает, что таких сигналов набирается слишком много, а оставлять Chipscope в устройстве, которое мы передаем пользователю в промышленную эксплуатацию и тестирование — не совсем корректно.
2. Обеспечить доступ через один из доступных интерфейсов ко всем регистрам, которые можно завести на этапе описания кода. Примеры реализации:
- Отображение регистров в адресное пространство устройства, если оно взаимодействует с внешним миром, например, через PCI Express.
- Обеспечение доступа через тот же UART. В идеале это должен быть максимально неубиваемый интерфейс.
3. Не забываем про светодиоды: более наглядного способа индикации работоспособности устройства с разработанной прошивкой еще не придумано.
Вот мы и рассмотрели самые распространенные ошибки и решения проблем при отладке устройств на базе FPGA. Надеемся, что осознанное написание кода и внимательное чтение документации позволит вам менять принцип 20/80 в свою пользу и ощутимо сократить время отладки и тестирования в общем плане проекта.
Конечно, в рамках одной статьи невозможно рассказать обо всех тонкостях отладки ПЛИС, отсюда и слово «искусство» в заголовке. Каждая ситуация требует осмысленного подхода и своего метода отладки.
Первая версия этой статьи была опубликована в блоге компании Promwad на Хабре.