Реализация базовых компонентов ЦОС : Комплексный умножитель




Оглавление
*О найденных опечатках и замечаниях просим сообщить admin@fpga-systems.ru
Аннотация
В данной статье рассматриваются особенности реализации одного из базовых компонентов цифровой обработки сигналов - комплексного умножителя. Разобраны способы разбиения умножения комплексных чисел на простейшие арифметические операции. Представлено RTL описание параметризируемого модуля на языке VHDL-2008.
1. Теоретическая часть
Комплексное умножение широко применяется при обработке комплексных сигналов. Оно встречается, например, при реализации таких блоков, как: цифровые повышающие/понижающие преобразователи, комплексные фильтры и корреляторы, блоки быстрого преобразования Фурье, схемы демодуляции и т.д.
Умножение двух комплексных чисел определяется как:
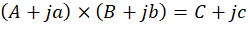
Если раскрыть скобки, то мы получим следующее выражение:
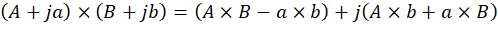
При этом:
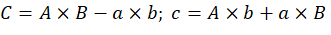
Схематическое изображение данных операций представлено на рисунке 1.
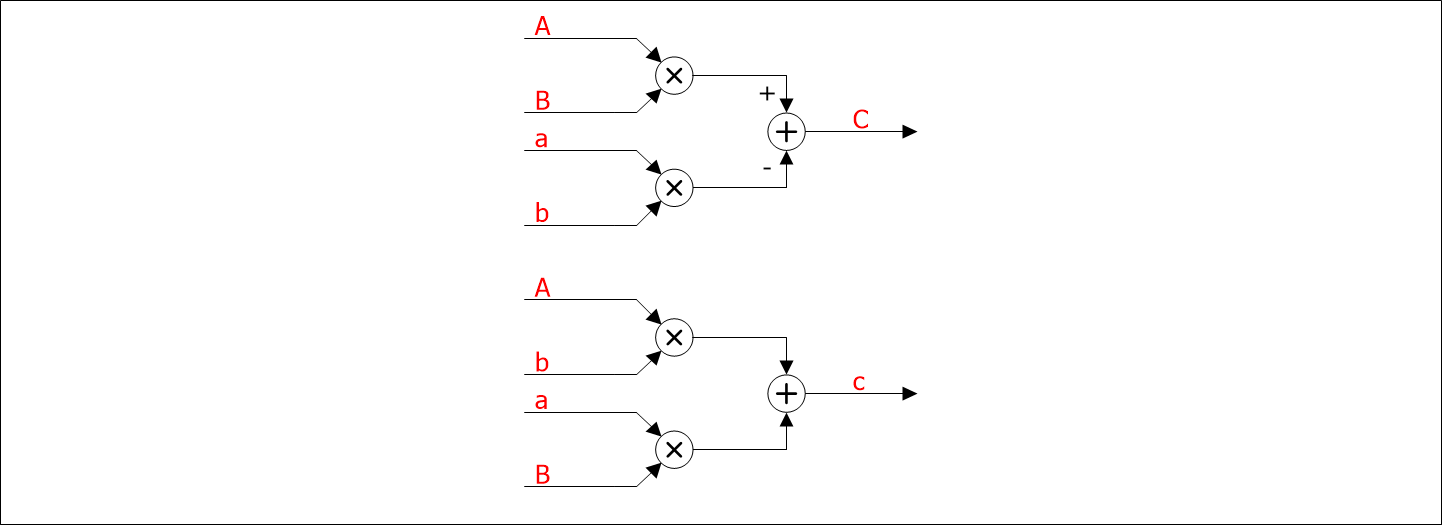
Рисунок 1 – Схема комплексного умножения
Для реализации данной схемы требуется четыре умножителя и два сумматора. Обозначим данную схему как «Схема 1».
Возможен и другой способ получения тех же значений:
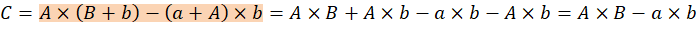
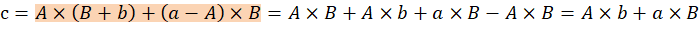
Схематическое изображение выделенных операций представлено на рисунке 2.
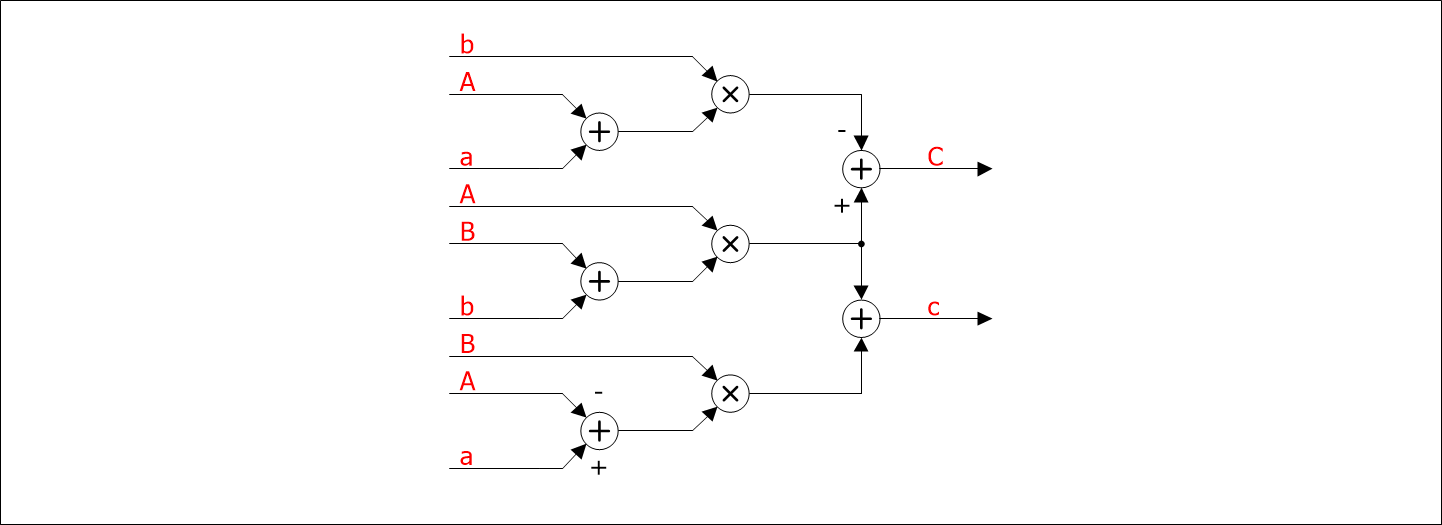
Рисунок 2 – Альтернативная схема комплексного умножения
Для реализации данной схемы требуется три умножителя и пять сумматоров. Обозначим данную схему как «Схема 2».
2. Функциональные схемы
Для достижения максимально возможной частоты обработки при реализации комплексного умножения на ПЛИС фирмы Xilinx следует использовать аппаратный блок DSP48, который содержит в себе умножитель, сумматор, предварительный сумматор, а так же наборы триггеров для входных/выходных данных и промежуточных результатов вычислений. В качестве примера будут рассмотрены схемы на основе DSP48E1.
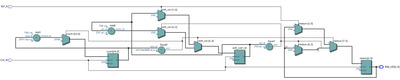
Один из таких вариантов реализации «Схемы 1» представлен на рисунке 3.
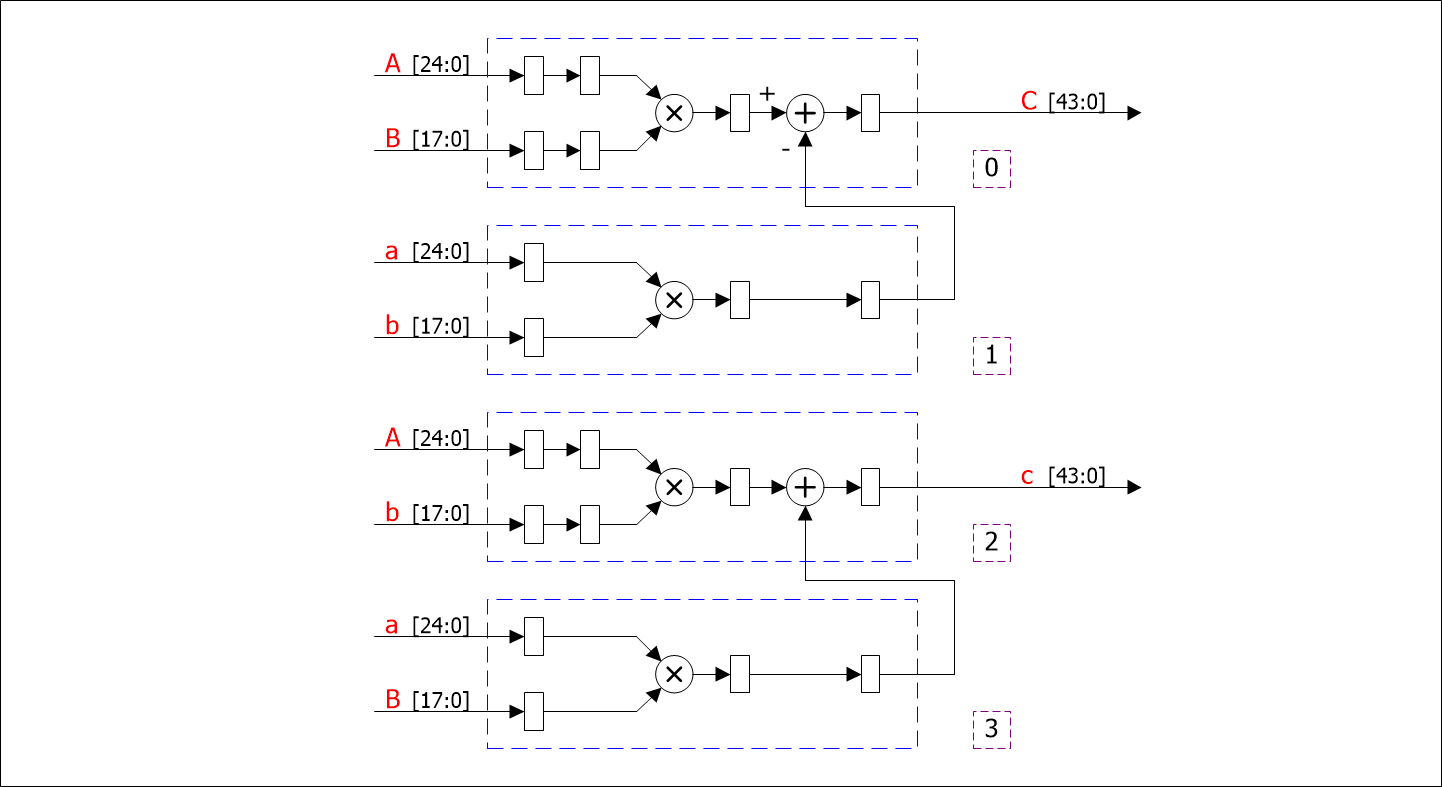
Рисунок 3 – реализация «Схемы 1» на блоках DSP48
Как видно из рисунка, данный вариант комплексного умножителя полностью укладывается в ресурсы аппаратных блоков DSP48E1 без использования дополнительной логики. Блоки 0 и 1 используются для расчета действительной части, 2 и 3 – мнимой части выходного числа.
Ввиду того, что умножитель DSP48E1 имеет разрядность 25x18, это накладывает ограничения на максимальную разрядность входных данных. В данном случае для входа A выбрана разрядность 25 бит, для входа B– 18 бит. Выход в таком случае будет иметь разрядность 44 бита.
Латентность данной схемы равняется четырем тактам.
«Схему 2» можно реализовать аналогичным образом, если использовать предварительный сумматор, как показано на рисунке 4.
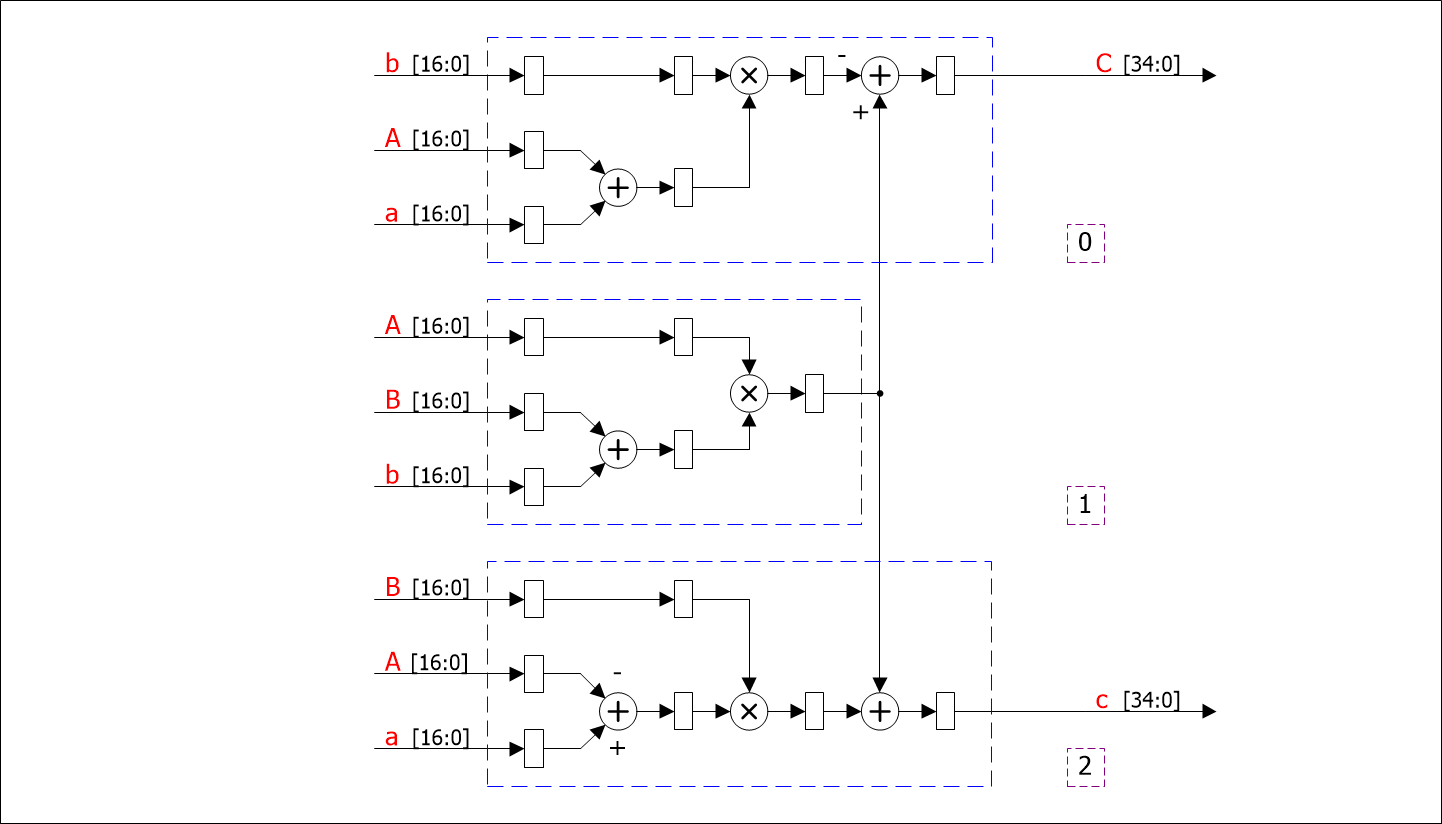
Рисунок 4 - реализация «Схемы 2» на блоках DSP48
Как видно из рисунка, данный вариант также полностью укладывается в ресурсы DSP48E1 и при этом используется на один аппаратный блок меньше. Блоки 0 и 1 используются для расчета действительной части, 1 и 2 – мнимой части выходного числа.
В данной схеме дополнительные ограничения на разрядность входных данных вносит тот факт, что данные поступают на предварительный сумматор и умножитель в различных комбинациях, поэтому максимальная разрядность входов A и B равна 17 битам. Выход в таком случае будет иметь разрядность 35 бит.
Латентность данной схемы также равняется четырем тактам.
3. RTL описание
Для описания комплексных чисел будет использоваться пользовательский тип t_iq, который объявлен в пакете pkg_rtl_modem_types и включает в себя два поля: i и q типа signed. VHDL 2008 позволяет объявлять данные поля без ограничений.
|
Листинг 1 – Объявление типа t_iq
Объявим интерфейс комплексного умножителя:
|
Листинг 2 – Интерфейс комплексного умножителя
Порт iCLK – сигнал тактирования модуля, iV– сигнал валидности входных данных, iAи iB– входные комплексные числа, oV– валидность выходных данных, oC– результат умножения.
Параметры g_a_dwи g_b_dwзадают разрядность соответствующих входов Aи B. Параметр g_typeопределяет, какая из схем умножения будет реализована: 1 – «схема 1», 2 – «схема 2».
Объявим сигналы для приема данных с входных и выдачи данных на выходные порты:
|
Листинг 3 – Описание основных сигналов
Сигнал pipe_v предназначен для задержки сигнала валидности со входа на выход, длина конвейера при этом определяется латентностью схемы (напомним, у обеих реализация умножителя она равна четырем).
Разрядность выходных данных определяется операциями умножения и сложения. Тело основного процесса, реализующего умножитель по «схеме 1» имеет вид:
|
Листинг 4 – Исходный код основного процесса «Схемы 1»
По сути, в теле описаны преобразования всех триггеров, представленных на рисунке 3. Аналогичным образом описывается «схема 2»:
|
Листинг 5 – Исходный код основного процесса «Схемы 2»
4. Синтез
Для синтеза будет использоваться Vivado версии 2020.2.
Vivado не позволяет синтезировать модули, порты которых имеют неограниченные поля, поэтому для синтеза мы напишем компонент – обертку:
|
Листинг 6 – Обертка комплексного умножителя
Синтезируем наш модуль по «схеме 1» с разрядностями 25 х 18.
В логе синтеза мы увидим следующее сообщение:

Как и ожидалось, все описанные в исходном коде триггеры были размещены в блоках DSP48. Видно, что для подачи результата умножения с одного аппаратного блока на сумматор другого используется порт PCIN.
Аналогично синтезируем наш модуль по «схеме 2» с разрядностями 17 х 17.
Лог для данного случая:

В данном случае, поскольку необходимо передать промежуточный результат с одного аппаратного блока на два других, используются порты PCIN и C, что снижает максимально возможную частоту обработки в сравнении со «схемой 1».
По итогу мы выяснили, что «схема 1» обладает преимуществами в разрядности входных данных и позволяет выжать максимум скорости из аппаратных блоков ПЛИС. Однако в проектах, где не требуется такая большая разрядность, «схема 2» позволяет экономить один DSP48 на каждую операцию комплексного умножения. Кроме того, максимальная рабочая частота чаще всего ограничена другими компонентами проекта, поэтому в этом плане разница между «схемами» несущественна.
Ссылки
1. https://github.com/vlotnik/rtl_modem - исходные коды, представленные в статье
2. https://www.xilinx.com/support/documentation/user_guides/ug193.pdf - гайд по использованию аппаратных блоков DSP48
3. https://www.xilinx.com/support/documentation/user_guides/ug479_7Series_DSP48E1.pdf - описание аппаратного блока DSP48E1
4. https://www.xilinx.com/support/documentation/user_guides/ug579-ultrascale-dsp.pdf - описание аппаратного блока DSP48E2